
La startup china acaba de publicar la versión preliminar de su modelo más ambicioso hasta la fecha. DeepSeek V4 llega en dos variantes -Pro y Flash- con soporte para 1 millón de tokens de contexto y una arquitectura MoE que planta cara directa a los modelos cerrados de OpenAI y Google.
El lanzamiento se produce justo un año después de que DeepSeek sacudiera Silicon Valley con su modelo R1, aquel que provocó una caída de un billón de dólares en bolsa. Esta vez la apuesta es todavía mayor: un modelo de código abierto bajo licencia MIT que, según sus propios benchmarks, supera a todos los modelos abiertos actuales en matemáticas, programación y razonamiento STEM.
Qué trae DeepSeek V4 Pro y en qué se diferencia de Flash
Las dos variantes comparten el soporte para contextos de 1 millón de tokens, pero ahí acaban las similitudes. DeepSeek V4 Pro cuenta con 1,6 billones de parámetros totales y activa 49.000 millones por cada token procesado. Flash, por su parte, se queda en 284.000 millones de parámetros totales con 13.000 millones activos.
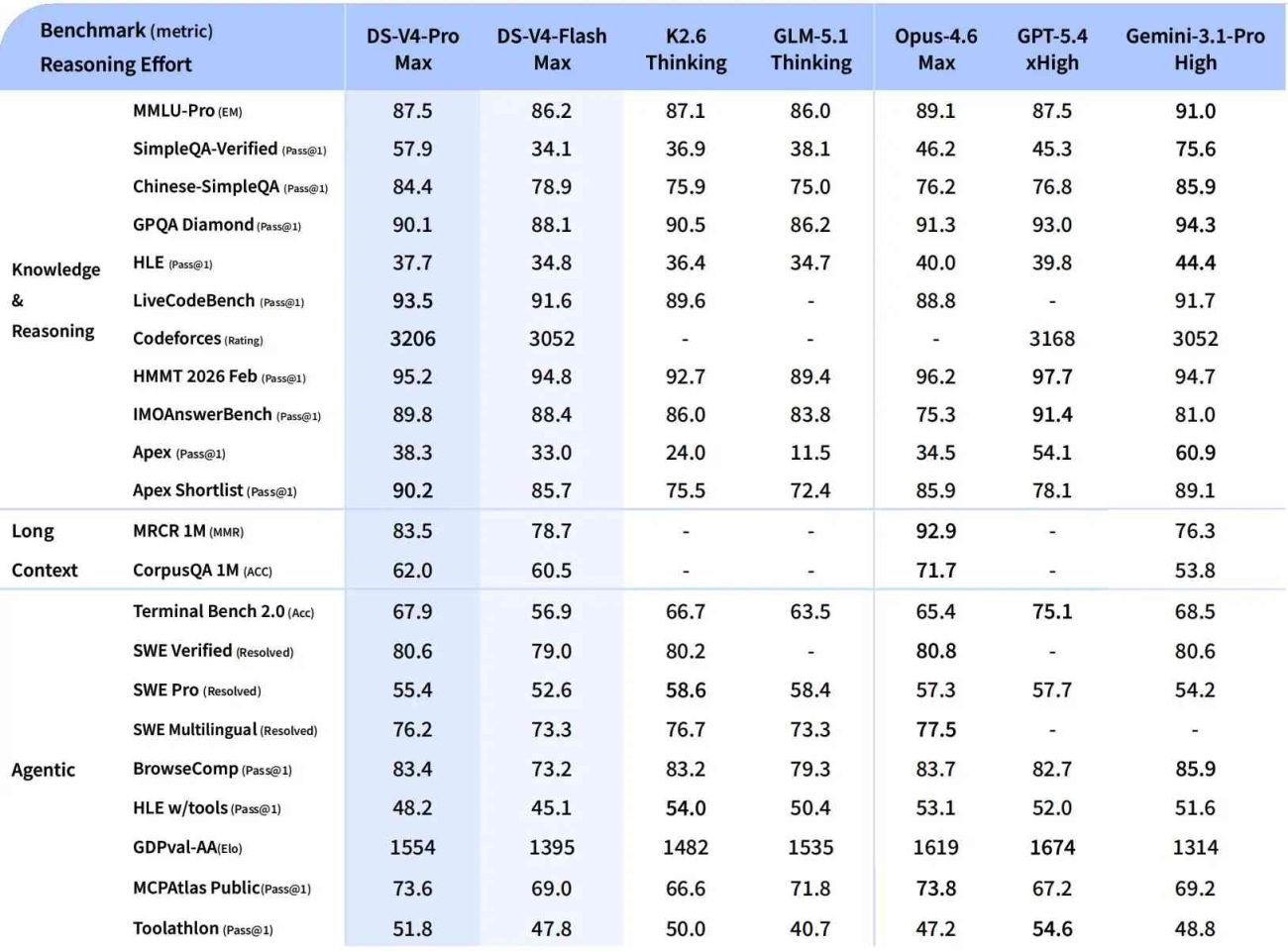
DeepSeek-V4-Pro supera a todos los modelos abiertos actuales y rivaliza con los mejores modelos de código cerrado en STEM y programación – DeepSeek
En la práctica, Pro está pensado para tareas complejas donde se necesita razonamiento profundo y capacidades de agente avanzadas. Flash apunta a escenarios donde la velocidad y el coste importan más que exprimir cada punto de benchmark. Y lo cierto es que la diferencia de rendimiento entre ambos no es tan grande como cabría esperar viendo la brecha de parámetros.
La arquitectura que hace posible el millón de tokens
DeepSeek ha desarrollado lo que llama Hybrid Attention Architecture, una combinación de Compressed Sparse Attention (CSA) y Heavily Compressed Attention (HCA). El resultado es que procesar contextos largos ya no dispara los costes de memoria como ocurría en generaciones anteriores. Comparado con V3.2, la mejora en consumo de recursos durante razonamiento de texto largo es considerable.
El modelo se entrenó con más de 32 billones de tokens usando precisión mixta FP4 y FP8. Los expertos MoE operan en FP4, lo que reduce el coste computacional sin sacrificar demasiada calidad en las respuestas.
Precios de API: aquí es donde DeepSeek golpea fuerte
Si algo ha definido la estrategia de DeepSeek desde sus inicios, es ofrecer rendimiento competitivo a precios que sus rivales no pueden igualar. Con V4 Flash, las entradas con acierto de caché cuestan apenas 0,028 dólares, y las salidas se quedan en 0,28 dólares. Para V4 Pro, los precios suben a 0,145 dólares en entrada (con caché) y 3,48 dólares en salida.
Son cifras que hacen viable usar un modelo de esta escala en producción sin arruinarse. Para equipos que trabajan con contextos largos -análisis de código base, documentación extensa, pipelines de agentes- la diferencia de costes frente a GPT o Claude puede ser brutal.
¿Dónde queda frente a la competencia cerrada?
Según los benchmarks publicados por DeepSeek, el V4 Pro solo queda por detrás de Gemini 3.1 Pro en conocimiento del mundo. En programación competitiva alcanza un Codeforces de 3.206, por encima del GPT-5.4. Eso sí, en recuperación de contexto largo todavía se queda lejos de los mejores modelos cerrados, y en evaluaciones económicas de productividad, tanto GPT-5.4 como Claude Opus 4.6 mantienen ventaja.
Lo relevante aquí no es que sea el mejor modelo en todo. Es que un modelo abierto y gratuito esté compitiendo en la misma liga que sistemas que cuestan diez veces más. Eso cambia las reglas para cualquier desarrollador o empresa que evalúe su stack de IA en 2026.
Los pesos del modelo están disponibles en Hugging Face y ModelScope, y la API actualizada ya permite acceder a ambas variantes. Por ahora solo procesa texto, aunque DeepSeek ha confirmado que trabaja en incorporar capacidades multimodales. Si quieres probarlo ahora mismo, tanto el Modo Instantáneo como el Modo Experto están activos en chat.deepseek.com.